等级聚类或者层级聚类是常用的数据分析方法,在R中,我们使用hclust()函数进行聚类分析。hclust()返回一个hclust类的对象。在本文中,让我们来揭开hclust对象的真面目。
首先生成一个随机的5x5矩阵,我们对矩阵的行进行聚类。
set.seed(123456)
m = matrix(rnorm(25), 5)
rownames(m) = letters[1:5]
hc = hclust(dist(m))
hc属于一个hclust的类。输入hc变量名打印出这个变量的一些基本信息。
hc
##
## Call:
## hclust(d = dist(m))
##
## Cluster method : complete
## Distance : euclidean
## Number of objects: 5
基本上就告诉你这是一个黑盒子,不告诉你其内部的结构。使用plot()函数可以绘制聚类图。
plot(hc)
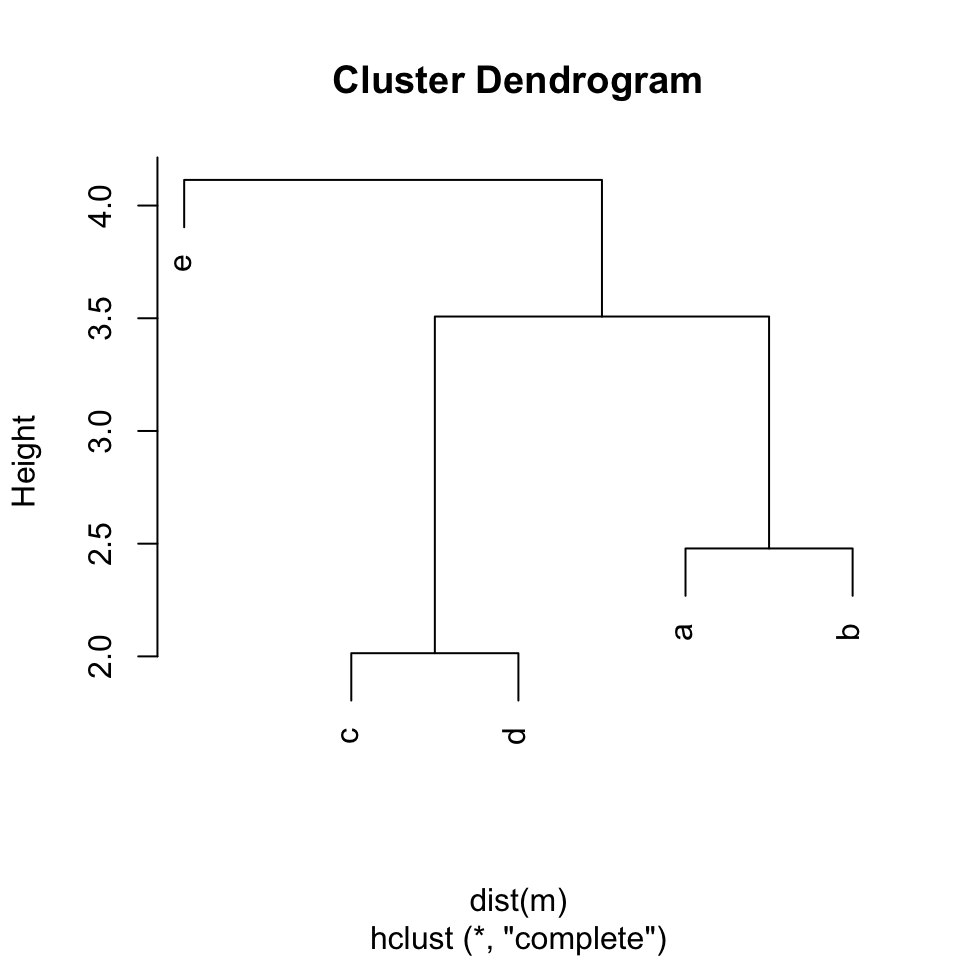
上面这两步是最标准的进行等级聚类分析的步骤,那么,hc变量中到底存储着什么信息呢?
本文就来揭示这个hc变量的内部结构。在遇到任何一个未知格式的对象时,一般我们使用str()来展示其内部结构:
str(hc)
## List of 7
## $ merge : int [1:4, 1:2] -3 -1 1 -5 -4 -2 2 3
## $ height : num [1:4] 2.01 2.48 3.51 4.11
## $ order : int [1:5] 5 3 4 1 2
## $ labels : chr [1:5] "a" "b" "c" "d" ...
## $ method : chr "complete"
## $ call : language hclust(d = dist(m))
## $ dist.method: chr "euclidean"
## - attr(*, "class")= chr "hclust"
可以看到,hc只是一个包含7个成员的简单列表。最后三个成员method,call和dist.method只是关于此变量的一些文字标记,我们跳过不谈。我们主要看前四个成员。
为了正确理解hc的格式,我们要对其中成员向量或者矩阵的顺序额外注意。我们首先介绍labels和order成员。
hc$labels
## [1] "a" "b" "c" "d" "e"
hc$order
## [1] 5 3 4 1 2
labels成员包含了原始变量的文字标签,其顺序和原始变量的顺序一致。在这里hc是来源于矩阵m,那么labels中值的顺序和m行的顺序一致。如果原始矩阵没有行名的话,labels是一个长度为零的向量。
order的顺序和labels不一样。等级聚类会对变量进行重排序,那么order中记录了排完序之后变量的下标。
hc$order
## [1] 5 3 4 1 2
第一个元素表示聚完类后,变量5在第一个位置上,变量3在第二个位置上,以此类推。如果我们使用原始矩阵的行名的话,聚类之后的顺序为:
hc$labels[hc$order]
## [1] "e" "c" "d" "a" "b"
也就是说,聚类之后,变量"e"在最左侧,然后分别是"c", "d", "a"和"b"。
现在让我们来看看merge和height成员。
hc$merge
## [,1] [,2]
## [1,] -3 -4
## [2,] -1 -2
## [3,] 1 2
## [4,] -5 3
hc$height
## [1] 2.014138 2.478801 3.507676 4.113743
第一眼看hc$merge,我们可能会说这是什么鬼,既有正的整数,又有负的整数。其实,merge使用不同的符号来表示聚类过程中不同类型的“节点”,比如说,这是一个变量/叶节点呢,还是一个子聚类/子树节点?
首先我们要知道,hclust()执行的是聚集式的聚类方式,也就是自底而上的方式。下图展示了hc中的四步聚类:
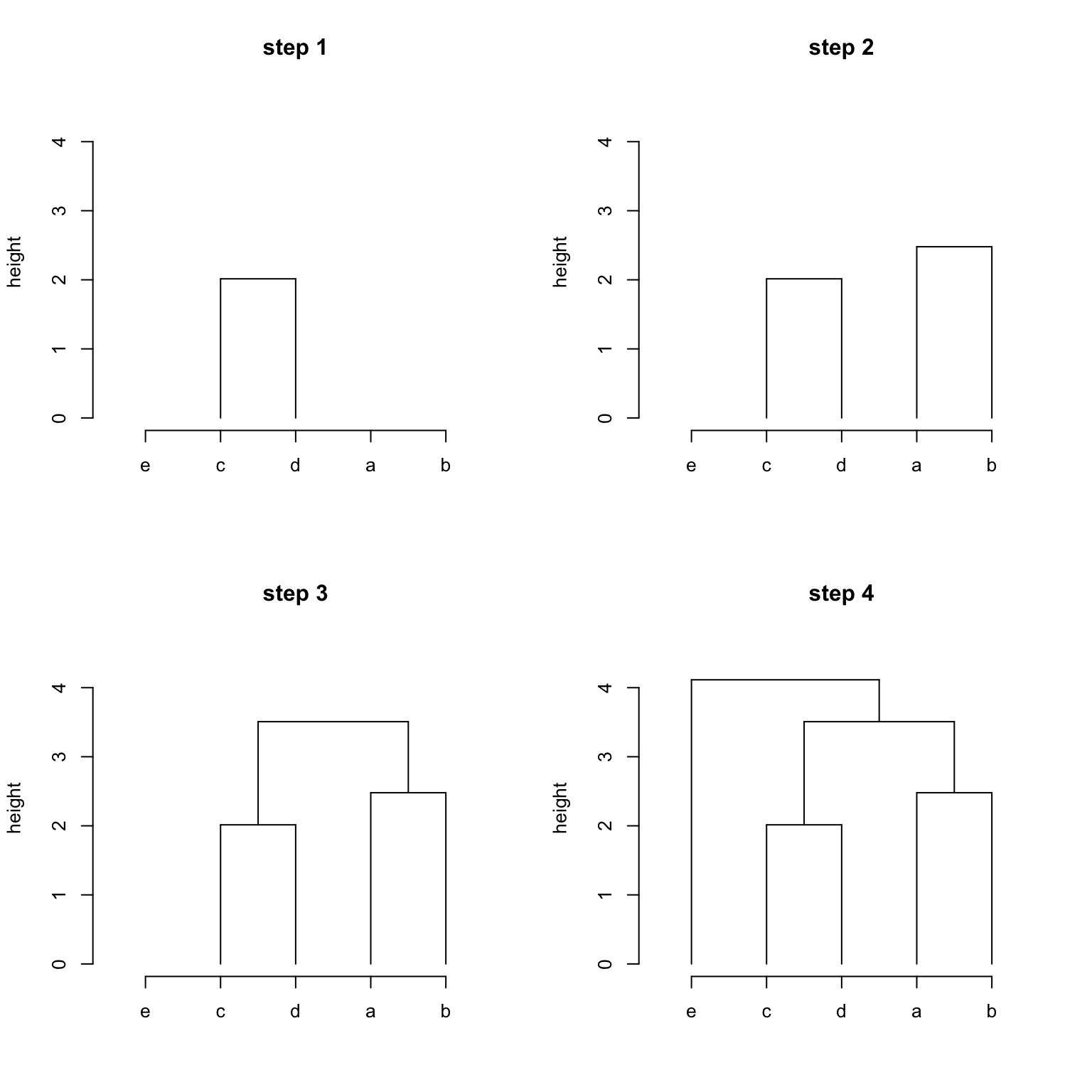
那么,其实merge中记录了聚类的步骤,第一行为聚类的第一步,第二行为聚类的第二步。每一行包含两个数据,表示把两个子节点聚成一类。其中如果值为负数时,这表示这是一个变量(或叶节点),那么其绝对值对应着这个变量的下标(第几号变量);如果值为正数的话,这表示这是一个子树,值对应着子树在merge中的下标(第几号子树)。
现在merge可以读作:
hc$merge
## [,1] [,2]
## [1,] -3 -4
## [2,] -1 -2
## [3,] 1 2
## [4,] -5 3
- 聚类第一步/
merge中第一行:变量3("c")和变量4("d")聚成一类。这个子树(或者可以看成变量3和4的父节点)的编号为1(因为是merge中的第一行)。 - 聚类第二步/
merge中第二行:变量1("a")和变量2("b")聚成一类。这个子树的编号为2。 - 聚类第三步/
merge中第三行:现在这行的两个数字都是正数,这表示要合并的两个都是聚类的子树,编号为1和2。这两个在前两步已经生成。 - 聚类第四步/
merge中第四行:这里有一个负数和一个正数,这表示要合并的是一个变量(变量5,"e")和一个子树(编号为3,在第三步中生成)。
hc$height中的元素和hc$merge中的行对应,就是每一个子树的高度。
现在看来,hclust对象的格式还是很简单的。
我们可以试着基于hc的内部格式绘制聚类图。让我们按照hc$merge中所记录的聚类的步骤一步一步来绘制。
第一步是绘制合并3号变量和4号变量的子树,我们知道这个子树的高度是hc$height[1],但是现在缺的是这些变量或者子树在x轴上的位置。这些位置很容易获得。
我们知道下面标签的顺序和聚类图上的顺序一致:
hc$labels[hc$order]
## [1] "e" "c" "d" "a" "b"
也就是说,"e"在位置1,"c"在位置2,… 但是这五个标签的顺序并不是原始顺序。在hc$merge中,其中的整数对应的是变量的原始顺序,例如-2表示在原始顺序中的2号变量。那么我们需要一个变量,其中记录着每个变量在聚类图上的位置,并且处于原始顺序中(也就是对应"a", "b", "c", "d", "e")。
我们可以首先创建一个有名字的向量,其中聚类之后的位置为值,名字为变量的标签。
# 1:5 是在x轴上的位置
map = structure(1:5, names = hc$labels[hc$order])
# 然后我们用这个有名字的向量获得对应原始顺序的变量
x = map[hc$labels]
x
## a b c d e
## 4 5 2 3 1
其实我们可以直接取hc$order的order获得这个向量。
x = order(hc$order)
x
## [1] 4 5 2 3 1
看起来有点绕,什么叫order的order?在hc$order中,值是变量的原始下标(也就是第几个变量),hc$order的下标(也就是1, 2, 3, 4, 5)对应着在聚完类后变量在x轴上的位置。
hc$order
value 5 3 4 1 2 # indices of items, i.e. item 5, item 3, ...
pos 1 2 3 4 5 # pos in x-axis in the plot
那么如果我们对hc$order(值为5, 3, 4, 1, 2)进行第二次order()时,在返回的变量中,第一个值是5, 3, 4, 1, 2中最小值的位置,就是1(1号变量)的位置是4(这个4是变量1在x轴上的位置),第二个值就是2(2号变量)的位置是5(变量2在x轴上的位置)。以此类推。这就意味着,order(hc$order)能够返回变量在聚类图上的位置,并且处于原始顺序中。
OK,现在我们有了所有的信息,可以一步一步的绘制聚类图了。我们按照hc$merge中的顺序:
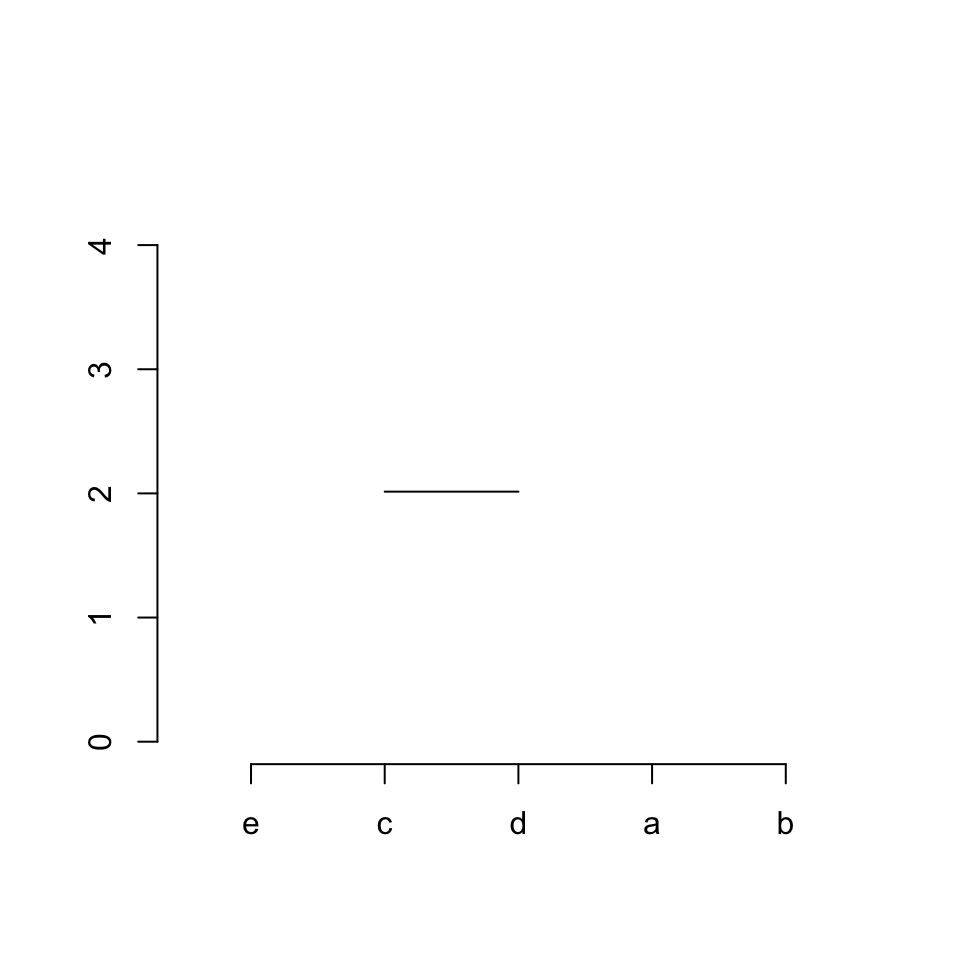
第一步/对应着hc$merge中的第一行,我们画一条线连接3号变量("c")和4号变量("d")。
plot(NULL, xlim = c(0.5, 5.5), ylim = c(0, max(hc$height)*1.1), axes = FALSE, ann = FALSE)
axis(side = 1, at = 1:5, labels = hc$labels[hc$order])
axis(side = 2)
# the first row in `merge` is '[1,] -3 -4'
segments(x[3], hc$height[1], x[4], hc$height[1])
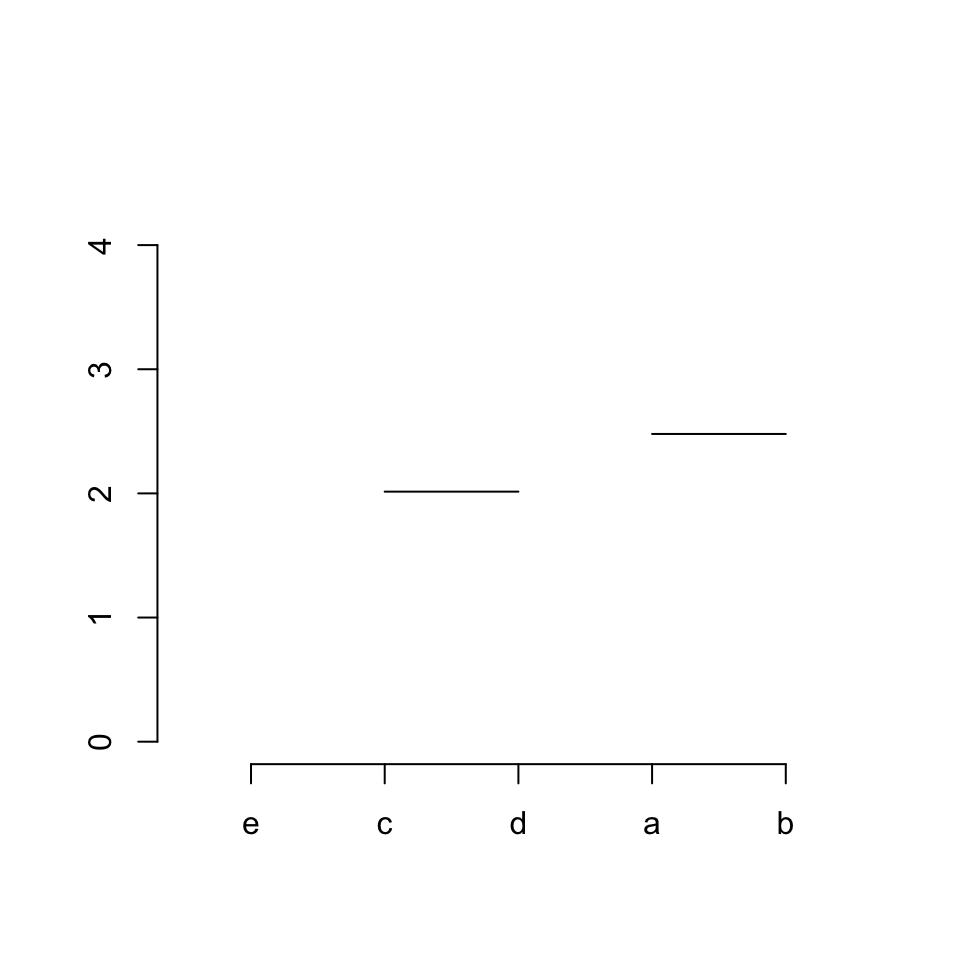
第二步/对应着hc$merge中的第二行,我们画一条线连接1号变量("a")和2号变量("b")。
plot(NULL, xlim = c(0.5, 5.5), ylim = c(0, max(hc$height)*1.1), axes = FALSE, ann = FALSE)
axis(side = 1, at = 1:5, labels = hc$labels[hc$order])
axis(side = 2)
segments(x[3], hc$height[1], x[4], hc$height[1])
# the second row in `merge` is '[2,] -1 -2'
segments(x[1], hc$height[2], x[2], hc$height[2])
第三步/对应着hc$merge中的第三行。现在这里有个新情况,第三步我们需要合并两个子树,我们通常连接两个子树的中点。计算子树1和子树2的中点很容易。子树1的中点就是其两个子节点(变量3和变量4)的中点,子树2的中点就是其两个子节点(变量1和变量2)的中点。
在下面的代码中,变量midpoint记录了中点的位置。
plot(NULL, xlim = c(0.5, 5.5), ylim = c(0, max(hc$height)*1.1), axes = FALSE, ann = FALSE)
axis(side = 1, at = 1:5, labels = hc$labels[hc$order])
axis(side = 2)
segments(x[3], hc$height[1], x[4], hc$height[1])
segments(x[1], hc$height[2], x[2], hc$height[2])
midpoint = numeric(0)
midpoint[1] = (x[3]+x[4])/2
midpoint[2] = (x[1]+x[2])/2
# the third row in `merge` is '[3,] 1 2'
segments(midpoint[1], hc$height[3], midpoint[2], hc$height[3])
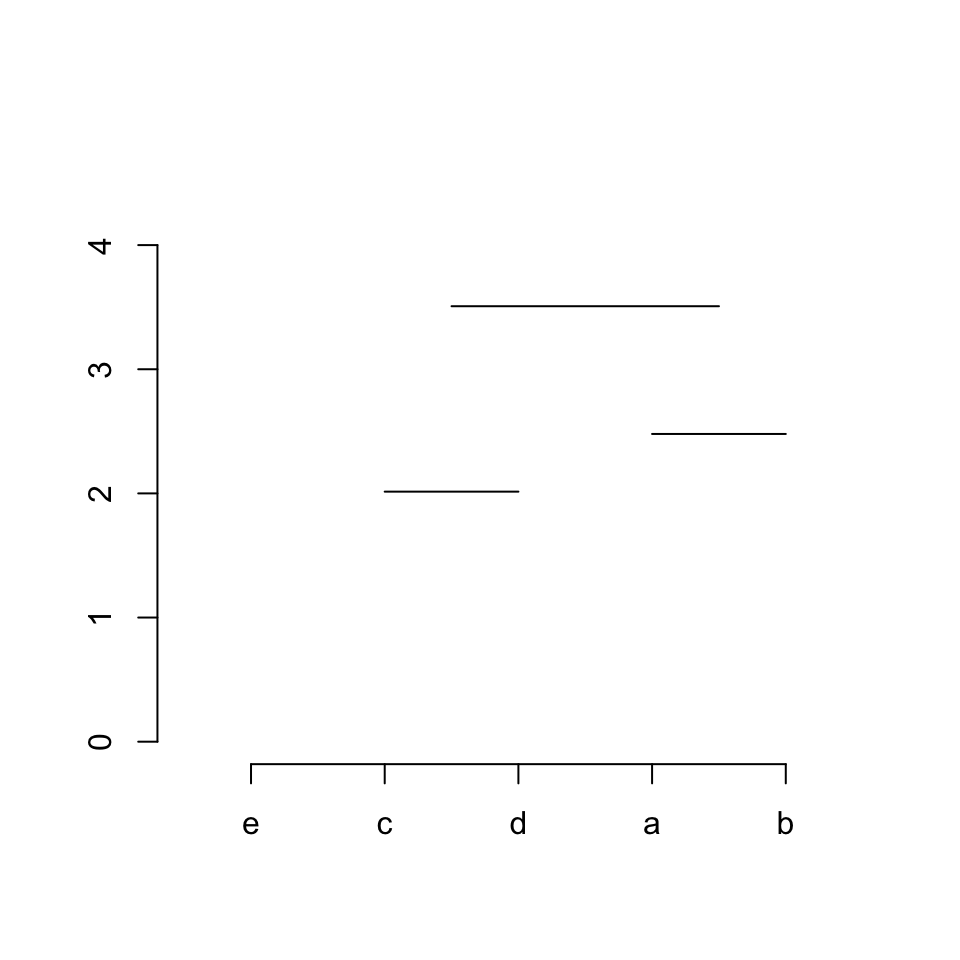
第四步/对应着hc$merge中的第四行。这一步合并5号变量和3号子树,同样我们需要先获得3号子树的中点(3号子树的中点是其两个子节点中点midpoint[1]和midpoint[2]的中点,看代码一目了然)。
plot(NULL, xlim = c(0.5, 5.5), ylim = c(0, max(hc$height)*1.1), axes = FALSE, ann = FALSE)
axis(side = 1, at = 1:5, labels = hc$labels[hc$order])
axis(side = 2)
segments(x[3], hc$height[1], x[4], hc$height[1])
segments(x[1], hc$height[2], x[2], hc$height[2])
midpoint = numeric(0)
midpoint[1] = (x[3]+x[4])/2
midpoint[2] = (x[1]+x[2])/2
segments(midpoint[1], hc$height[3], midpoint[2], hc$height[3])
midpoint[3] = (midpoint[1] + midpoint[2])/2
# the third row in `merge` is '[4,] -5 3'
segments(x[5], hc$height[4], midpoint[3], hc$height[4])
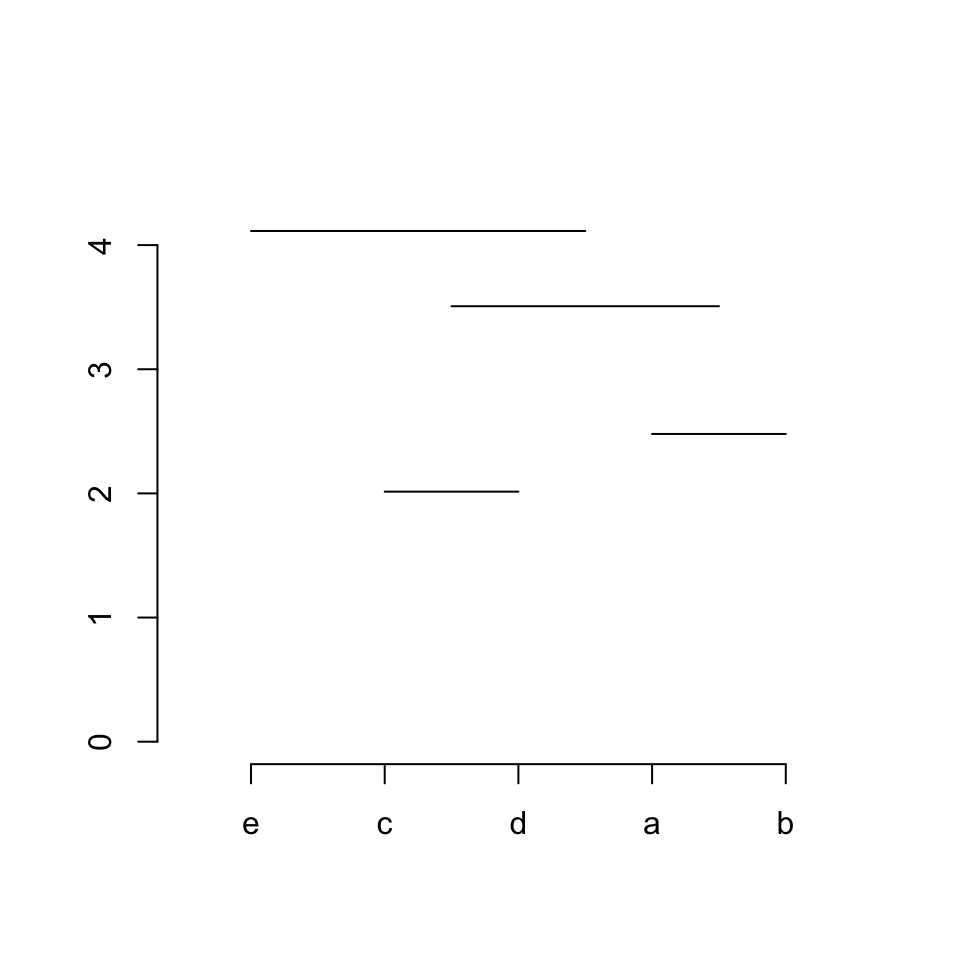
我们可以添加垂直的线条,让其看起来像一个完整的聚类树。
plot(NULL, xlim = c(0.5, 5.5), ylim = c(0, max(hc$height)*1.1), axes = FALSE, ann = FALSE)
axis(side = 1, at = 1:5, labels = hc$labels[hc$order])
axis(side = 2)
segments(x[3], hc$height[1], x[4], hc$height[1])
segments(x[3], 0, x[3], hc$height[1])
segments(x[4], 0, x[4], hc$height[1])
segments(x[1], hc$height[2], x[2], hc$height[2])
segments(x[1], 0, x[1], hc$height[2])
segments(x[2], 0, x[2], hc$height[2])
midpoint = numeric(0)
midpoint[1] = (x[3]+x[4])/2
midpoint[2] = (x[1]+x[2])/2
segments(midpoint[1], hc$height[3], midpoint[2], hc$height[3])
segments(midpoint[1], hc$height[3], midpoint[1], hc$height[1])
segments(midpoint[2], hc$height[3], midpoint[2], hc$height[2])
midpoint[3] = (midpoint[1] + midpoint[2])/2
segments(x[5], hc$height[4], midpoint[3], hc$height[4])
segments(midpoint[3], hc$height[4], midpoint[3], hc$height[3])
segments(x[5], 0, x[5], hc$height[4])
为了重复利用上面的代码,我们可以把它们放在一个函数中。这个函数plot_hc()很简单,其中四个if-else代码块处理下面四个不同的条件:
- 两个子节点都是变量(或者叶节点)
- 左子节点是叶节点,右子节点是一个子树
- 左子节点是一个子树,右子节点是叶节点
- 两个子节点都是子树
plot_hc = function(hc) {
x = order(hc$order)
nobs = length(x)
if(length(hc$labels) == 0) {
hc$labels = as.character(seq_along(hc$order))
}
plot(NULL, xlim = c(0.5, nobs + 0.5), ylim = c(0, max(hc$height)*1.1), axes = FALSE, ann = FALSE)
axis(side = 1, at = 1:nobs, labels = hc$labels[hc$order])
axis(side = 2)
merge = hc$merge
order = hc$order
nr = nrow(merge)
midpoint = numeric(nr)
for(i in seq_len(nr)) {
child1 = merge[i, 1]
child2 = merge[i, 2]
if(child1 < 0 && child2 < 0) { # both are leaves
segments(x[ -child1 ],
hc$height[i],
x[ -child2 ],
hc$height[i])
midpoint[i] = (x[ -child1 ] + x[ -child2 ])/2
segments(x[ -child1 ], hc$height[i], x[ -child1 ], 0)
segments(x[ -child2 ], hc$height[i], x[ -child2 ], 0)
} else if(child1 < 0 && child2 > 0) {
segments(x[ -child1 ],
hc$height[i],
midpoint[ child2 ],
hc$height[i])
midpoint[i] = (x[ -child1 ] + midpoint[ child2 ])/2
segments(x[ -child1 ], hc$height[i], x[ -child1 ], 0)
segments(midpoint[ child2 ], hc$height[i], midpoint[ child2 ], hc$height[ child2 ])
} else if(merge[i, 1] > 0 && merge[i, 2] < 0) {
segments(midpoint[ child1 ],
hc$height[i],
x[ -child2 ],
hc$height[i])
midpoint[i] = (midpoint[ child1 ] + x[ -child2 ])/2
segments(midpoint[ child1 ], hc$height[i], midpoint[ child1 ], hc$height[ child1 ])
segments(x[ -child2 ], hc$height[i], x[ -child2 ], 0)
} else {
segments(midpoint[ child1 ],
hc$height[i],
midpoint[ child2 ],
hc$height[i])
midpoint[i] = (midpoint[ child1 ] + midpoint[ child2 ])/2
segments(midpoint[ child1 ], hc$height[i], midpoint[ child1 ], hc$height[ child1 ])
segments(midpoint[ child2 ], hc$height[i], midpoint[ child2 ], hc$height[ child2 ])
}
}
}
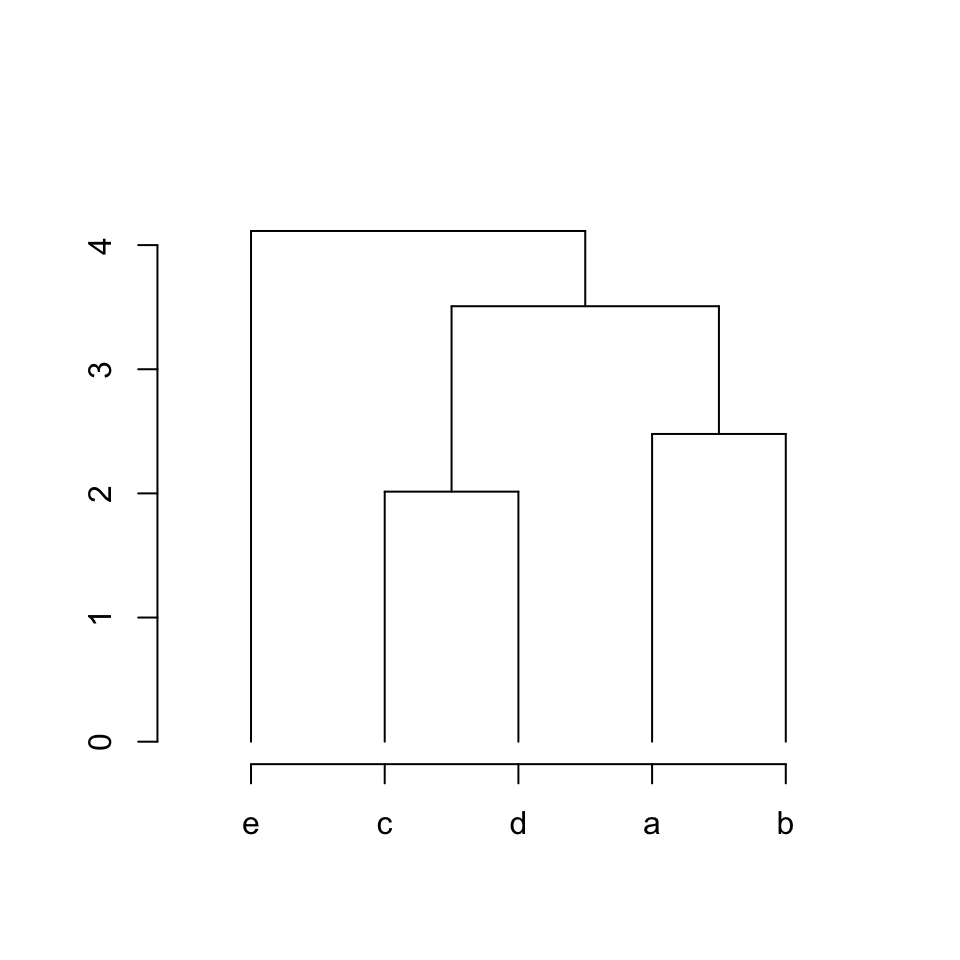
我们试一试这个函数:
plot_hc(hc)
或者试一个更大的聚类结果:
m2 = matrix(rnorm(1000), nrow = 100)
hc2 = hclust(dist(m2))
plot_hc(hc2)
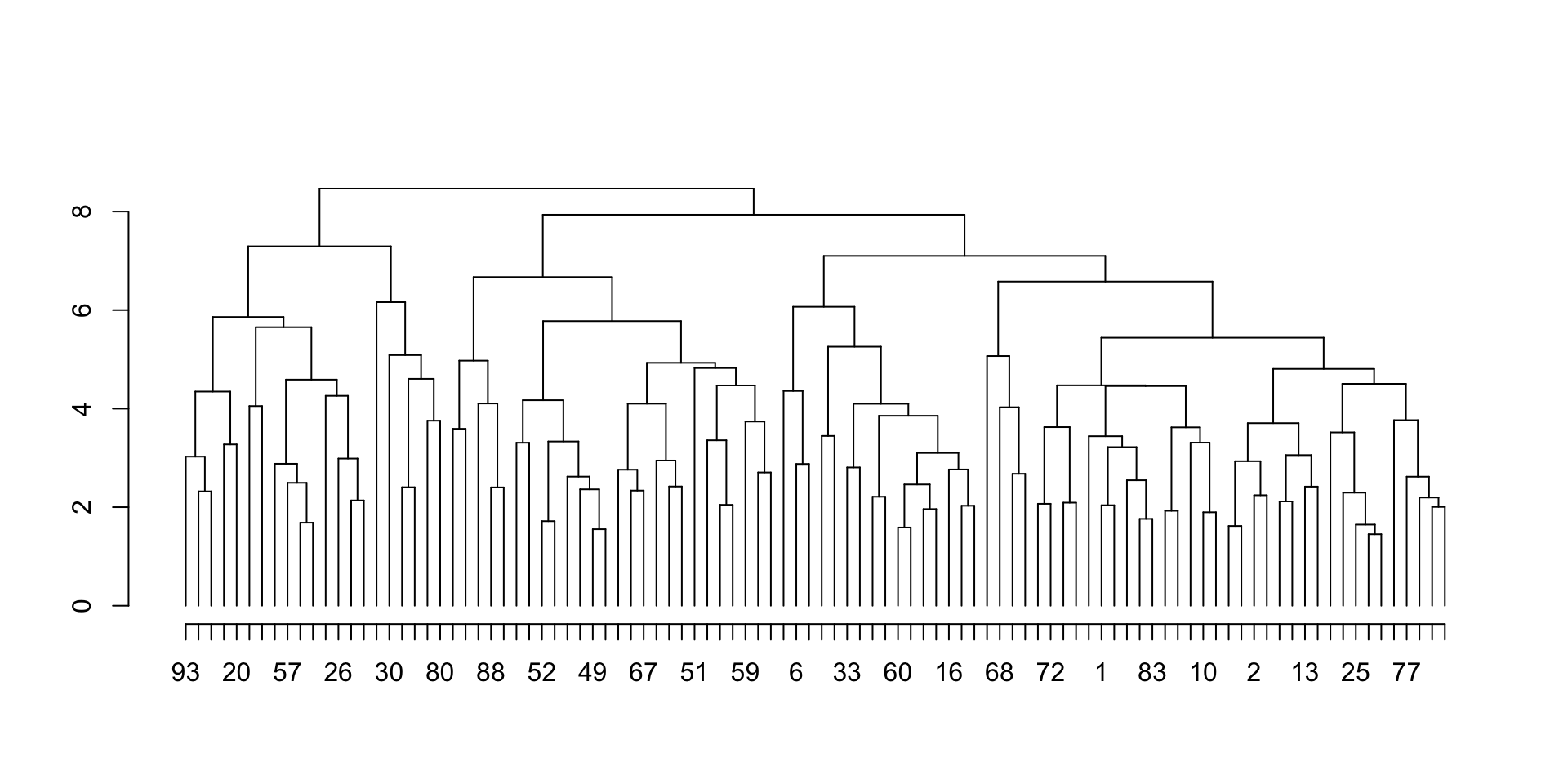
到这里,通常我们会有很大的成就感。因为plot_hc()是基于一个微小的数据测试和编写的,现在居然在很大的数据上能够成功运行。
下面我们来看,给定一个父节点(top_x, top_y),和两个子节点(left_x, left_y),(right_x, right_y),我们来定义如何连接这三个节点。
默认的连接方式是连接下面四个点:
x-coordinates: left_x, left_x, right_x, right_x
y-coordinates: left_y, top_y, top_y, right_y
在plot_hc()中,让我们将绘制父节点和子节点的代码抽象化。我们引入一个函数parent_children_connections(),其中我们可以自定义如何绘制连接方式。
plot_hc = function(hc) {
x = order(hc$order)
nobs = length(x)
if(length(hc$labels) == 0) {
hc$labels = as.character(seq_along(hc$order))
}
plot(NULL, xlim = c(0.5, nobs + 0.5), ylim = c(0, max(hc$height)*1.1), axes = FALSE, ann = FALSE)
axis(side = 1, at = 1:nobs, labels = hc$labels[hc$order])
axis(side = 2)
merge = hc$merge
order = hc$order
height = hc$height
nr = nrow(merge)
midpoint = numeric(nr)
for(i in seq_len(nr)) {
child1 = merge[i, 1]
child2 = merge[i, 2]
if(child1 < 0 && child2 < 0) { # both are leaves
midpoint[i] = (x[ -child1 ] + x[ -child2 ])/2
parent_children_connections(
x[-child1], 0,
midpoint[i], height[i],
x[-child2], 0
)
} else if(child1 < 0 && child2 > 0) {
midpoint[i] = (x[ -child1 ] + midpoint[ child2 ])/2
parent_children_connections(
x[-child1], 0,
midpoint[i], height[i],
midpoint[child2], height[child2]
)
} else if(child1 > 0 && child2 < 0) {
midpoint[i] = (midpoint[ child1 ] + x[ -child2 ])/2
parent_children_connections(
midpoint[child1], height[child1],
midpoint[i], height[i],
x[-child2], 0
)
} else {
midpoint[i] = (midpoint[ child1 ] + midpoint[ child2 ])/2
parent_children_connections(
midpoint[child1], height[child1],
midpoint[i], height[i],
midpoint[child2], height[child2]
)
}
}
}
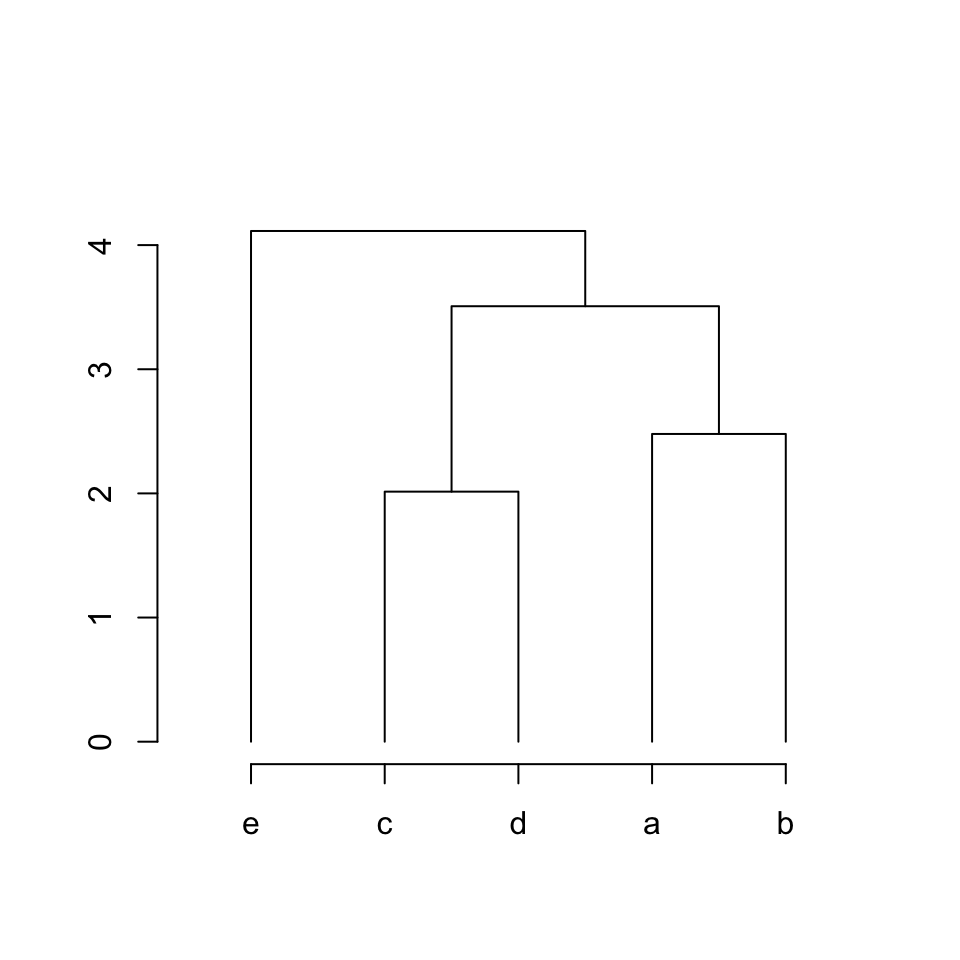
下面是默认的连接父节点和两个子节点的方式:
parent_children_connections = function(left_x, left_y, top_x, top_y, right_x, right_y) {
lines(c(left_x, left_x, right_x, right_x),
c(left_y, top_y, top_y, right_y))
}
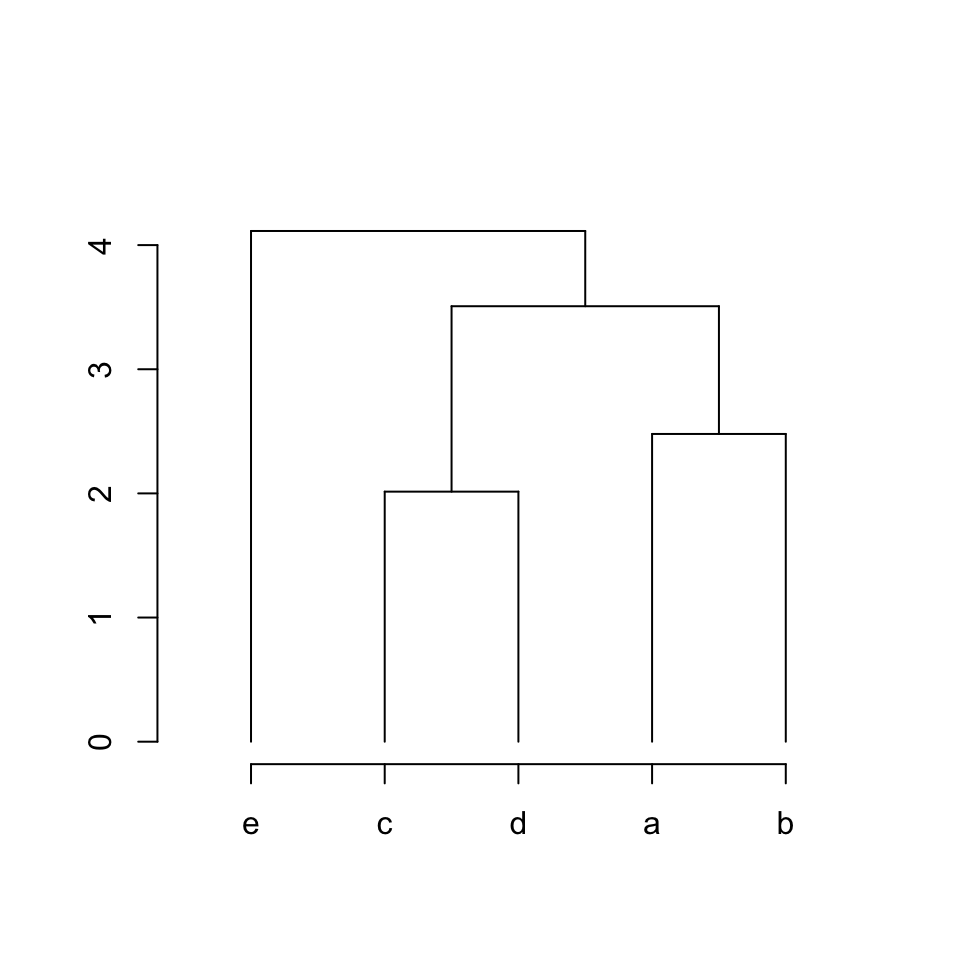
plot_hc(hc)
我们可以定义一个新的方式,让连接方式呈三角形状:
x-coordinates: left_x, top_x, right_x
y-coordinates: left_y, top_y, right_y
parent_children_connections = function(left_x, left_y, top_x, top_y, right_x, right_y) {
lines(c(left_x, top_x, right_x),
c(left_y, top_y, right_y))
}
plot_hc(hc)
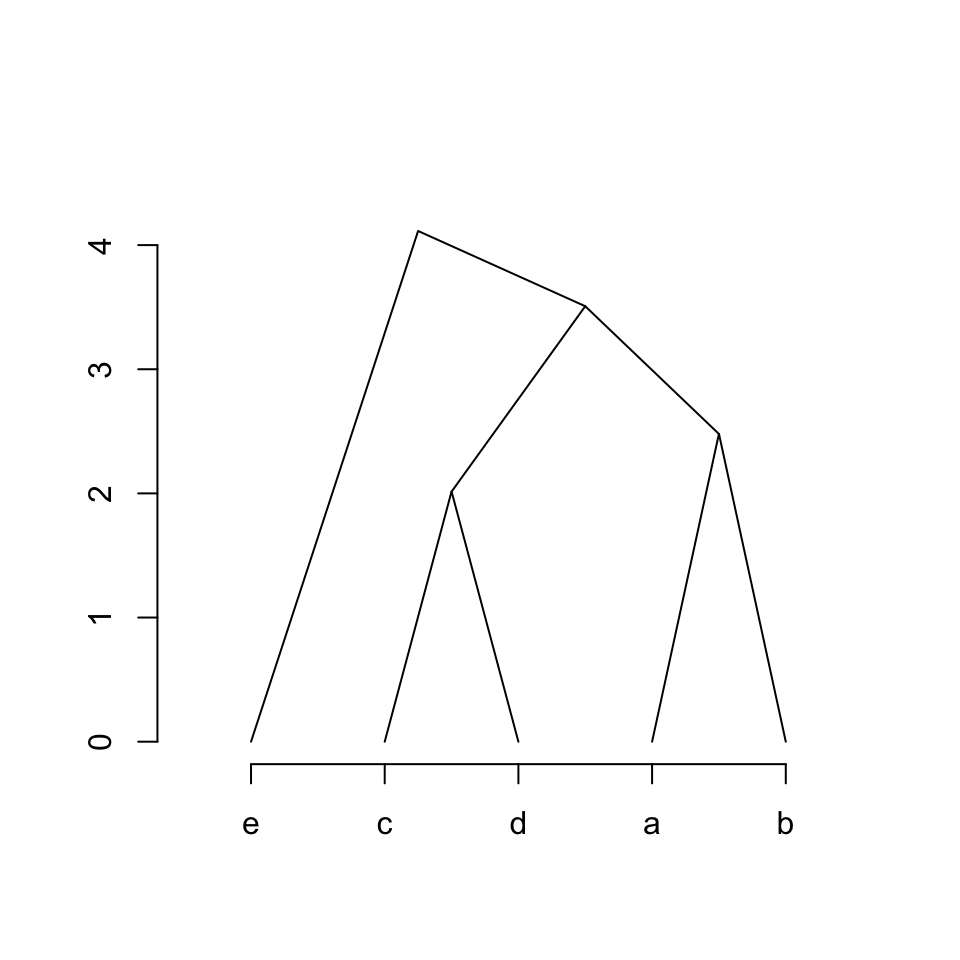
同理,你可以自定义parent_children_connections()来实现其他连接方式,例如使用贝泽尔曲线。
本文使用 CC BY-NC-SA 4.0 协议发布。