Send R code/R scripts/shell commands to LSF cluster
Zuguang Gu ( z.gu@dkfz.de )
2025-03-13
Source:vignettes/bsub_intro.Rmd
bsub_intro.RmdLoad the library:
We suggest to use bsub directly on the node that has the same file system as the computing nodes. If the file system is different from the computing nodes, you can only monitor jobs status while you cannot submit jobs.
bsub package can submit R code (by bsub_chunk()), R scripts (by bsub_script()) and bash commands (by bsub_cmd()) to the LSF cluster purely inside the R session. We suggest to save the output into permanent files in the jobs while not directly retrieving the results on the fly.
Send R code
bsub_chunk() submits the R chunk. The code chunk should be embraced by {...}. For example, NMF::nmf() normally takes very long time to run. We submit the NMF analysis to the cluster and save the results as an RDS file.
bsub_chunk(name = "example", memory = 10, hours = 10, cores = 4,
{
fit = NMF::nmf(...)
# you better save `fit` into a permanent file in an absolute path
saveRDS(fit, file = "/path/to/fit.rds")
})In the following examples, we use Sys.sleep(5) to simulate a chunk of code which runs for a short time.
bsub_chunk(
{
Sys.sleep(5)
})The bsub_chunk() prints the bsub command and the value returned by bsub_chunk() is the job ID from LSF cluster.
Job settings
Set job name, memory, running time and number of cores:
bsub_chunk(name = "example", memory = 10, hours = 10, cores = 4,
{
Sys.sleep(5)
})If name is not specified, an internal name calculated by digest::digest() on the chunk is automatically assigned. The unit of memory is GB.
Call Rscript
The R chunk is saved into a temporary R script and called by Rscript command when it is executed on the cluster. A lot of LSF clusters have customized installation of R, which means, calling Rscript is specific for every LSF cluster, thus, you need to configure how to call the Rscript command. By default, it simply calls Rscript with the default R version installed on the cluster.
To set Rscript calling with a specific version or in a specific path, you need to configure the bsub_opt$call_Rscript option. The value for bsub_opt$call_Rscript should be a user-defined function where the R version in the only argument. The default value for bsub_opt$call_Rscript is
function(version) "Rscript"which ignores the R version. If you want to specify Rscritp with a specific path, you can set bsub_opt$call_Rscript as:
bsub_opt$call_Rscript = function(version) "/the/absolute/path/of/Rscript"To make it more flexible, the R version can be used when setting how to call Rscript. By default, when installing R, R will installed into folder with the version name of e.g. /.../3.6/..., thus, if there are several R versions are installed on your cluster, you can set bsub_opt$call_Rscript as:
library(GetoptLong)
bsub_opt$call_Rscript = function(version) {
qq("/the/absolute/path/of/@{gsub('\\.\\d+$', '', version)}/Rscript")
}Here qq() is from GetoptLong package which does variable interpolation. You can use similar packages such as glue here.
Later, the R version can be easily switched by setting bsub_opt$R_version or the R_version argument in bsub_chunk() (The value of R_version is sent to call_Rscript function). E.g:
bsub_chunk(name = "example", R_version = "3.6.0",
{
Sys.sleep(5)
})Or set R_version as a global parameter:
bsub_opt$R_version = "3.6.0"
bsub_chunk(name = "example",
{
Sys.sleep(5)
})On DKFZ ODCF cluster, software with different versions are managed by Environment Modules. bsub_opt$call_Rscript was set as follows:
function(version) {
qq("module load gcc/7.2.0; module load java/1.8.0_131; module load R/@{version}; Rscript")
}The module loading for gcc/7.2.0 and java/1.8.0_131 ensures that R packages depending on specific C/Java libraries can be successfully loaded. So, if R_version is set to 4.0.0, the Rscript call would be
module load gcc/7.2.0; module load java/1.8.0_131; module load R/4.0.0; Rscriptwhich makes sure the Rscript from R-4.0.0 is used.
Similarlly, if you use conda for managing different versions of software, you can also choose R with different versions by setting a proper bsub_opt$call_Rscript. Let assume you have conda environments for different R versions with the name schema R_$version (e.g. R_3.6.0), then you can set bsub_opt$call_Rscript as:
bsub_opt$call_Rscript = function(version) {
qq("conda activate R_@{version}; Rscript")
}Bash environment
In previous examples, we load the gcc/7.2.0 and java/1.8.0_131 modules, or activate the conda environment as parts of the command callling Rscript. These bash-level initialization can also be set by sh_head which adds shell commands as header in the bash script that is used for job submission. E.g., we can do the other way:
bsub_opt$call_Rscript = function(version) qq("module load R/@{version}; Rscript")
bsub_chunk(name = "example", sh_head = c("module load gcc/7.2.0", "module load java/1.8.0_131"),
{
Sys.sleep(5)
})Or set sh_head as a global option:
bsub_opt$call_Rscript = function(version) qq("module load R/@{version}; Rscript")
bsub_opt$sh_head = c("module load gcc/7.2.0", "module load java/1.8.0_131")
bsub_chunk(name = "example",
{
Sys.sleep(5)
})One usage of this functionality is to load pandoc module if the rmarkdown is used in the code chunk (on DKFZ ODCF cluster):
bsub_chunk(name = "example", sh_head = "module load pandoc/2.2.1",
{
library(rmarkdown)
render(...)
})Load other packages
The packages that are needed can be directly added in the code chunk:
bsub_chunk(name = "example",
{
library(package1)
library(package2)
Sys.sleep(5)
})Or assign by packages argument:
bsub_chunk(name = "example", packages = c("package1", "package2"),
{
Sys.sleep(5)
})Or set it as a global parameter:
bsub_opt$packages = c("package1", "package2")
bsub_chunk(name = "example",
{
Sys.sleep(5)
})There is a special value _in_session_ for packages argument that loads all packages in the current R session.
library(foo)
library(bar)
bsub_chunk(name = "example", packages = "_in_session_",
{
Sys.sleep(5)
})Other R variables
The R variables that are defined outside the code chunk and need to be used inside the code chunk can by specified by variables argument:
foo = 1
bsub_chunk(name = "example", variables = "foo",
{
bar = foo
Sys.sleep(5)
})variables argument has a special value _all_functions_ that loads all functions defined in the global environment.
f1 = function() 1
f2 = function() 2
bsub_chunk(name = "example", variables = "_all_functions_",
{
f1()
f2()
Sys.sleep(5)
})R variables shared between jobs
If multiple jobs use the same variables, they can be specified via share argument. In this case, the shared variables are only saved into temporary files once. Note these temporary are not deleted automatically since they do not know whether all jobs which reply on them are finished. Users need to manually delete them when all jobs are done.
foo = 1
for(i in 1:10) {
bsub_chunk(name = paste0("example", i), share = "foo",
{
bar = foo
Sys.sleep(5)
})
}The workspace image
If you have too many external variables that are used in the code chunk or they are used in multiple jobs, you can directly save the workspace or the objects as an image and specify the image argument:
save.image(file = "/path/foo.RData")
# or
# save(var1, var2, ..., file = "...")
bsub_chunk(name = "example", image = "/path/foo.RData",
{
...
Sys.sleep(5)
})Or set the image file as a global parameter:
save.image(file = "/path/foo.RData")
bsub_opt$image = "/path/foo.RData"
bsub_chunk(name = "example",
{
...
Sys.sleep(5)
})Absolute paths should be used instead of relative paths.
Please note, image files can be shared between different jobs and they are not deleted after all the jobs are finished, as a comparison, variables are saved into separated temporary files for different jobs even when the variable names are the same, and they are deleted after the jobs are finished.
The working directory
If the code chunk replies on the working directory, it can be specified by working_dir argument:
bsub_chunk(name = "example", working_dir = "/path"
{
Sys.sleep(5)
})Or set it as a global parameter:
bsub_opt$working_dir = "/path"
bsub_chunk(name = "example",
{
Sys.sleep(5)
})Note it is not recommended to let all file pathes in the jobs be relative or be affected by the working directory. It is recommended to use absolute path everywhere in the job.
Retrieve the last variable
The last variable in the code chunk can be saved by setting save_var = TRUE and retrieved back by retrieve_var() by specifying the job ID.
retrieve_var() waits until the job is finished.
job_id = bsub_chunk(name = "example2", save_var = TRUE,
{
Sys.sleep(10)
1+1
})
retrieve_var(job_id)However, it is not recommended to directly retrieve the returned value from the code chunk. Better choice is to save the variable into permanent file in the code chunk so you don’t need to rerun the code in the future which normally has very long runing time, E.g.:
bsub_chunk(name = "example",
{
...
save(...)
# or
saveRDS(...)
})Rerun the job
There is a flag file to mark whether the job was successfully finished or not. If the job has been successfully done, the job with the same name will be skipped. enforce argument controls how to rerun the jobs with the same names. If it is set to TRUE, jobs will be rerun no matter they are done or not.
bsub_chunk(name = "example", enforce = FALSE,
{
Sys.sleep(5)
})enforce can be set as a global parameter:
bsub_opt$enforce = FALSE
bsub_chunk(name = "example",
{
Sys.sleep(5)
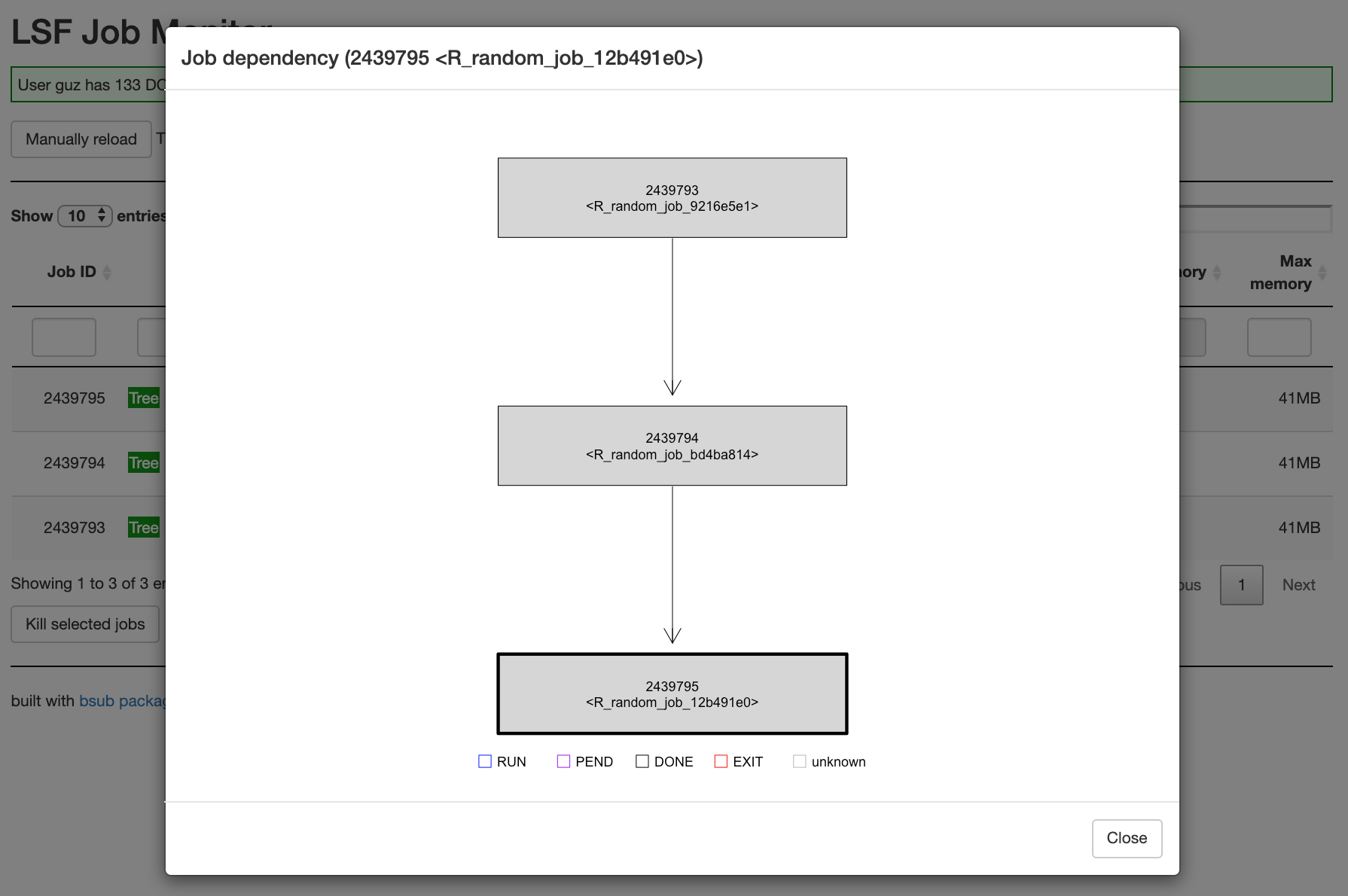
})Job dependency
Since bsub_chunk() returns the job ID, it is can be used to specify the dependency in other jobs. The value for dependency can be a vector of job IDs.
job1 = bsub_chunk(name = "example1",
{
Sys.sleep(5)
})
bsub_chunk(name = "example2", dependency = job1,
{
Sys.sleep(5)
})Temporary and output directory
bsub_chunk() has two arguments temp_dir and output_dir. temp_dir is used for the temporary R script and sh files. output_dir is used for the flag files and the output files from LSF cluster.
bsub_chunk(name = "example", temp_dir = ..., output_dir = ...,
{
Sys.sleep(5)
})They can be set as global parameters. The value of output_dir is by default set as the same as temp_dir.
bsub_opt$temp_dir = ...
bsub_opt$output_dir = ...
bsub_chunk(name = "example",
{
Sys.sleep(5)
})To remove temporary files in temp_dir, run clear_temp_dir() function.
Run code chunk from a script
You can run code chunk from a script by specifying the starting line number and the ending line number. The R script is specified by script argument, the starting line number and the ending line number are specified by start and end arguments. (Note this functionality has not been tested yet.)
bsub_chunk(name = "example",
script = "/path/foo.R",
start = 10, end = 20, ...)Assuming you are editing foo.R very offen and the line numbers that you want to run change from time to time, you can add tags in the R script and specifying start and end by those tags. In following example which is the source code of foo.R, we add tags for the code chunk we want to run:
...
# BSUB_START
you code chunk here
# BSUB_END
...Then you can specify start and end by regular expressions to match them:
bsub_chunk(name = "example",
script = "/path/foo.R",
start = "^# BSUB_START",
end = "^# BSUB_END", ...)Run jobs locally
Setting local = TRUE directly runs the code chunk in the same R session (do not submit to the cluster).
bsub_chunk(name = "example", local = TRUE,
{
cat("blablabla...\n")
})Submit jobs over different parameters
The nice thing for bsub package is you can programmatically submit many of jobs. Assuming we have a list of samples where the sample IDs are saved in sample_id variable, and a list of parameters (in parameters variable) to test, we want to apply the analysis by analyze() function to each sample with each parameter per single job. We can submit all the jobs as follows:
library(GetoptLong)
for(sid in sample_id) {
for(param in parameters) {
bsub_chunk(name = qq("analysis_@{sid}_@{param}"),
variables = c("sid", "param"),
packages = ..., other_arguments...,
{
res = analyze(sid, param)
saveRDS(res, file = qq("/path/to/result_@{sid}_@{param}.rds"))
})
}
}Send R script
bsub_script() submits the job from R scripts. The major arguments are the same as in bsub_chunk().
bsub_script("/path/of/foo.R", name = ..., memory = ..., cores = ..., ...)If the R script needs command-line arguments, they can be specified by argv.
bsub_script("/path/of/foo.R", argv = "--a 1 --b 3", ...)When you have a list of jobs with the same argument names but with different argument values, you can construct argv by glue::glue() or GetoptLong::qq() to construct the argv string:
library(GetoptLong)
for(a in 1:10) {
for(b in 11:20) {
bsub_script("/path/foo.R", argv = qq("-a @{a} --b @{b}"), ...)
}
}The command-line arguments of your R script can also specified as arguments of bsub_script(), but with . prefix.
bsub_script("/path/foo.R", .a = 1, .b = 3, ...)Then for the same example previously for submitting a list of jobs, it can be written as:
for(a in 1:10) {
for(b in 11:20) {
bsub_script("/path/foo.R", .a = a, .b = b, ...)
}
}The R scripts should be used in the absolute paths.
Note the bash environment can be initialized by setting the sh_head option.
Send other shell commands
bsub_cmd()submits shell commands. Basically it is similar as bsub_script():
bsub_cmd("samtools sort ...", name = ..., memory = ..., cores = ..., ...)
bsub_cmd(c("cmd1", "cmd2", ...), name = ..., memory = ..., cores = ..., ...)The binary and the arguments should all be set in the first argument of bsub_cmd(). Remember to use glue::glue() or GetoptLong::qq() to construct the commands if they contain variable arguments, e.g:
Job Summary
bjobs() or just entering bjobs gives a summary of running and pending jobs. Job status (by default is RUN and PEND) is controlled by status argument. Number of most recent jobs is controlled by max argument. Filtering on the job name is controlled by filter argument. In the following example, we submit four tiny jobs.
for(i in 1:4) {
bsub_chunk(name = paste0("example_", i),
{
Sys.sleep(5)
})
}
bjobsThere is one additional column RECENT in the summary table which shows the order of the jobs with the same job name. The most recent job has the value 1.
for(i in 1:2) {
bsub_chunk(name = "example",
{
Sys.sleep(5)
})
}
bjobs(status = "all", filter = "example")brecent() by default returns 20 most recent jobs of “all” status. You can simply type brecent without the brackets.
brecentThere are some helper functions which only list running/pending/done/failed jobs:
bjobs_runningbjobs_pendingbjobs_donebjobs_exit
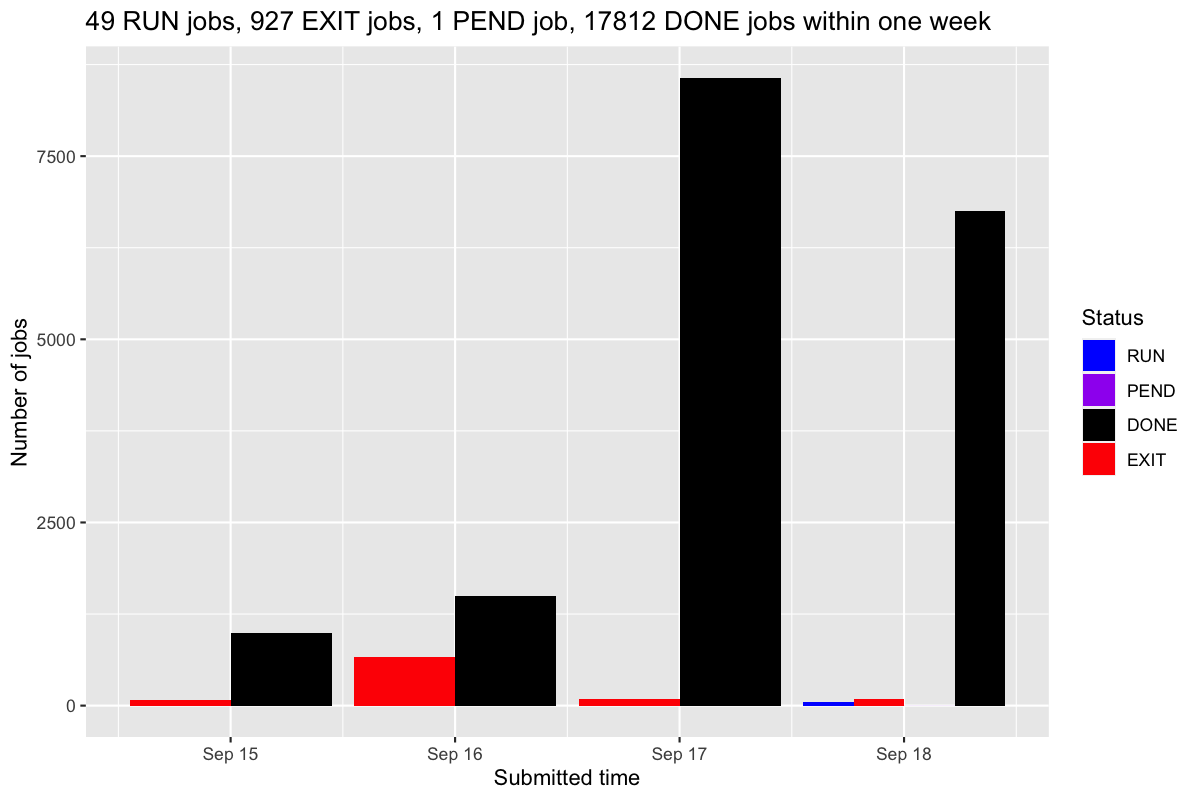
bjobs_barplot() makes a barplot of numbers of jobs per day.
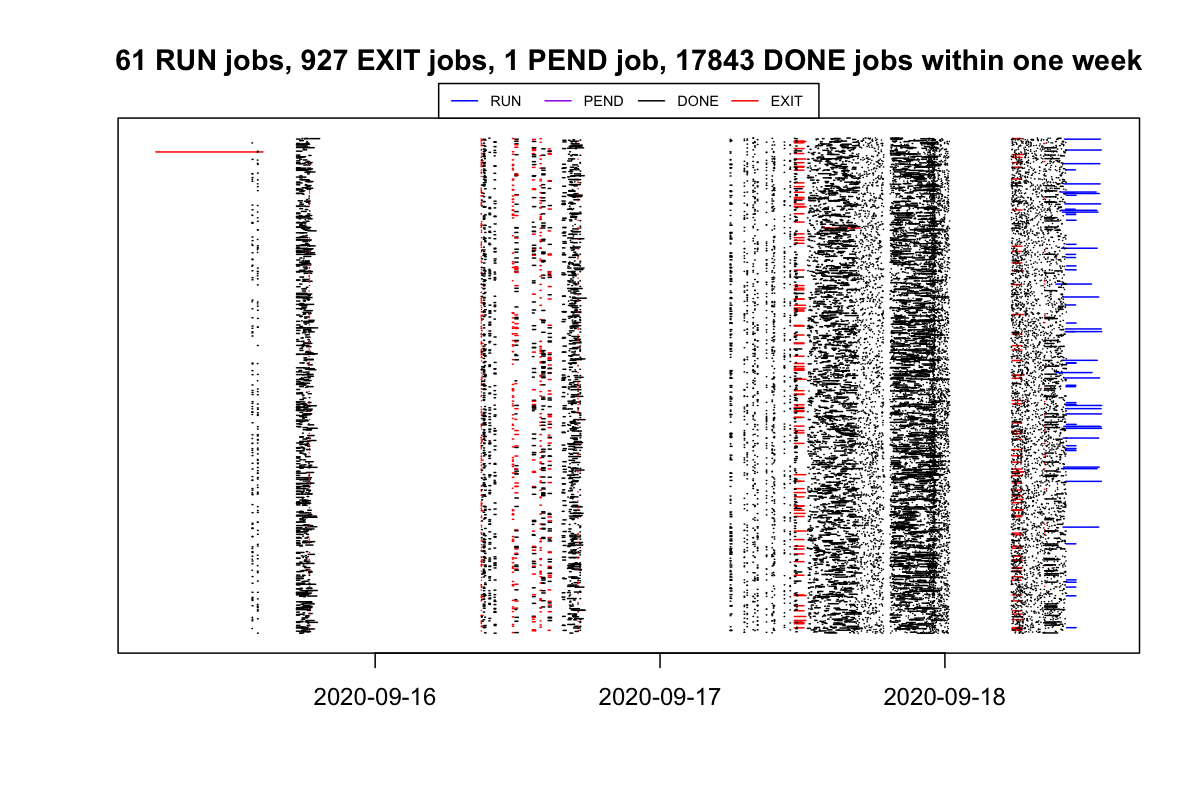
bjobs_timeline() draws the duration of each job. In the plot, each segment represents a job and the width corresponds to its duration.
Other functions
-
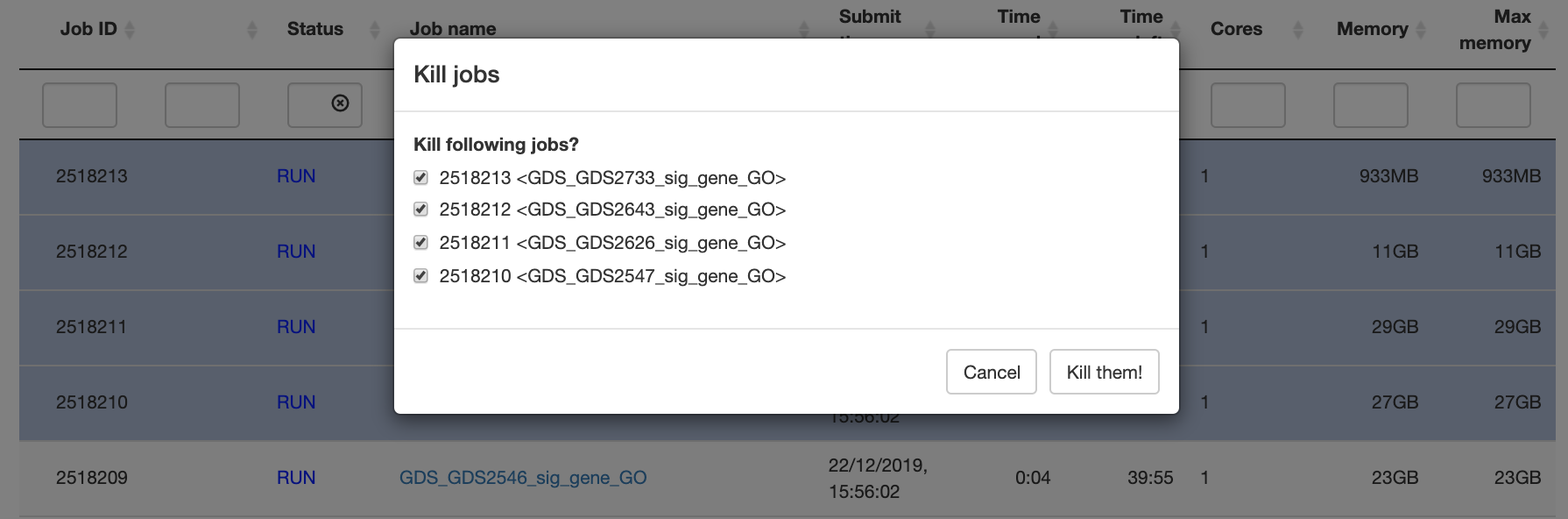
bkill(job_id)kills a job or a list jobs. -
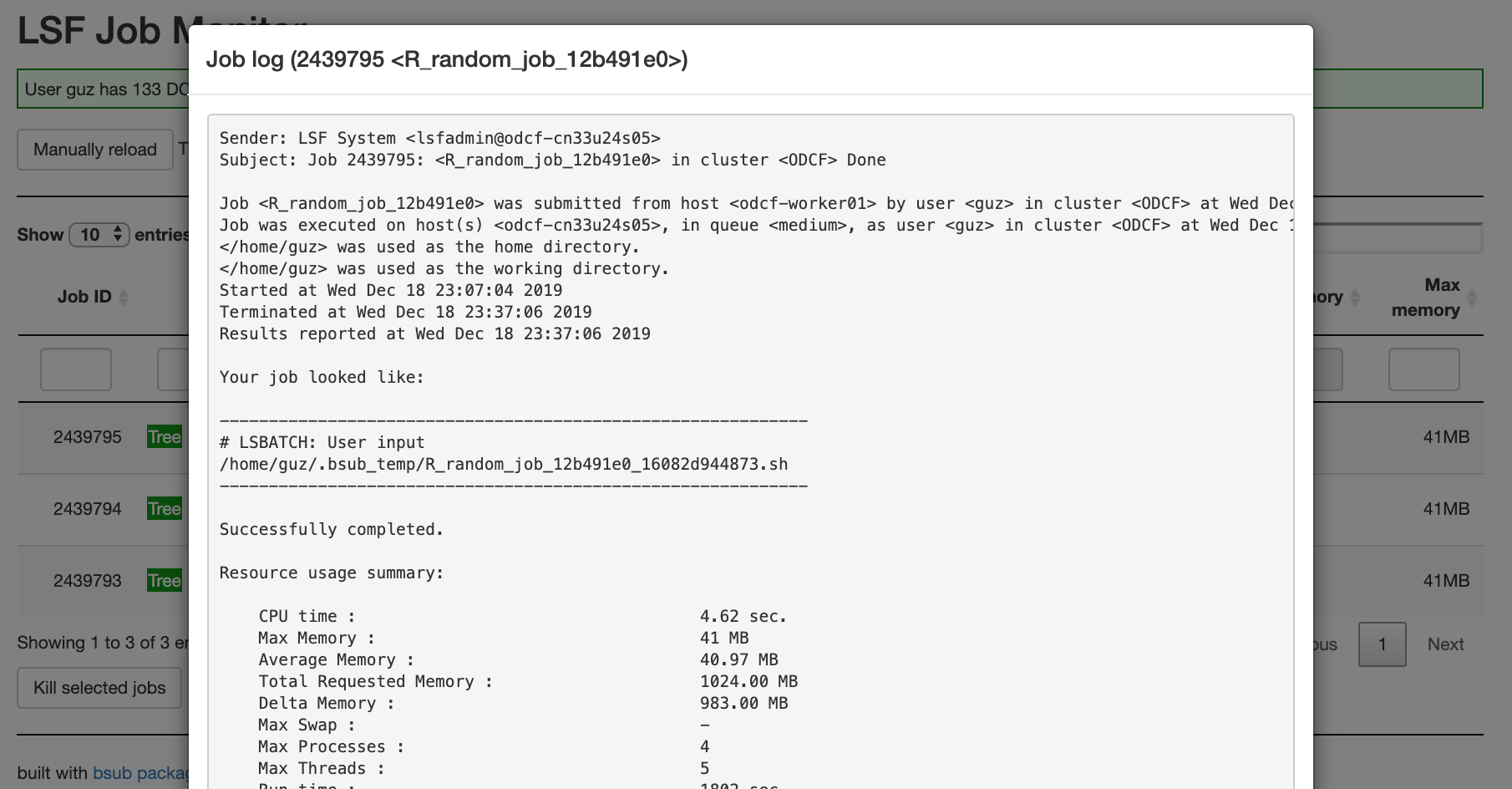
job_log(job_id)prints the log of a specified running/finished/failed job. A vector of jobs can also be sent at the same time that last 10 lines of each job are printed. -
check_dump_files()searches the dump files (core.xxxby LSF cluster or.RDataTmpxxxby R). -
ssh_connect()establishes the SSH connection to the submission node if it is lost.
Global Parameters
Type bsub_opt gives you a list of global options. Values can be set by in a form of bsub_opt$opt = value. All the values can be reset by bsub_opt(RESET = TRUE).
bsub_optOr a more readable text:
bconfInteractive job monitor
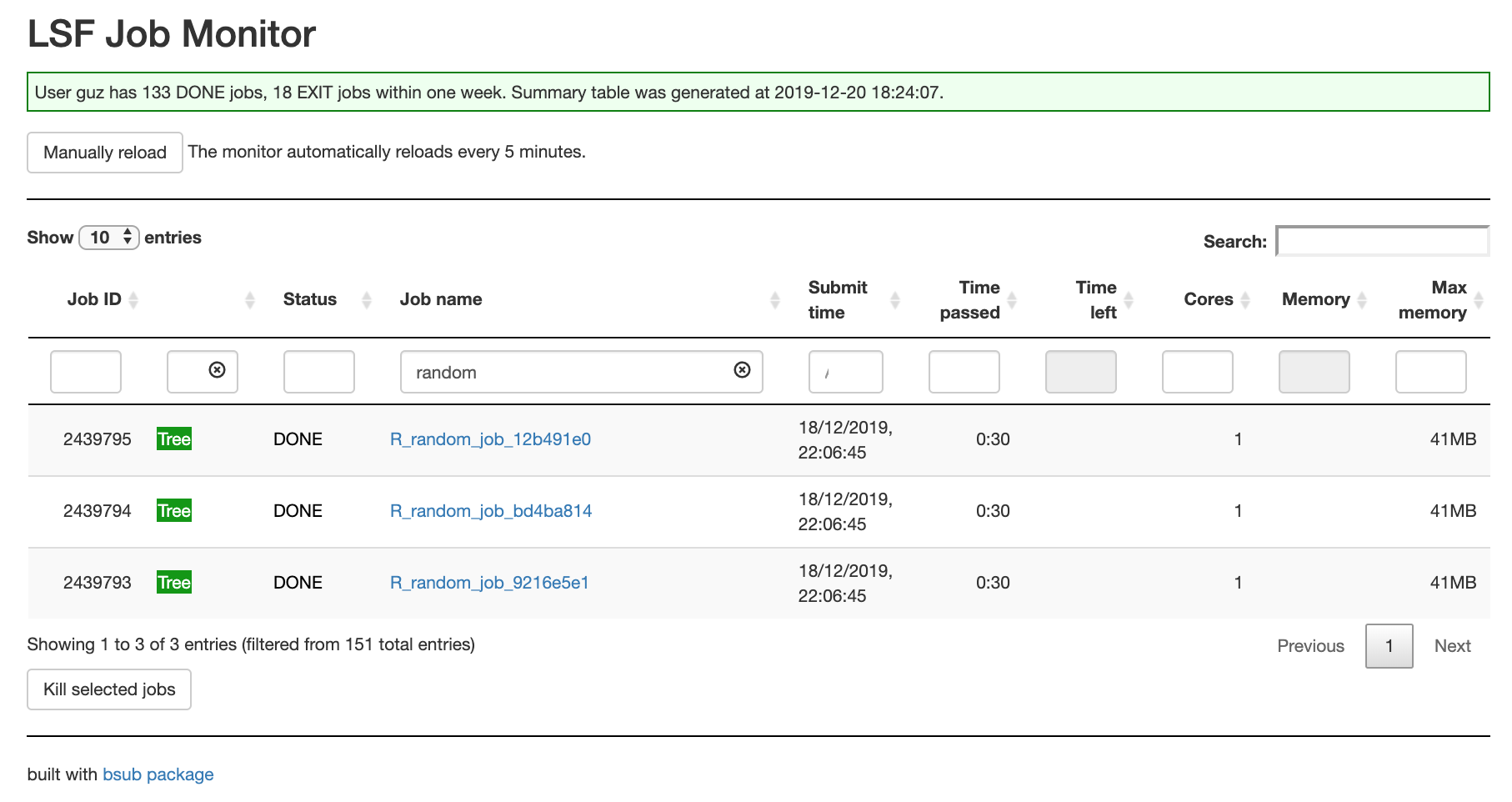
Simply running monitor() opens a shiny app where you can query and manage jobs.
monitor()Following are examples of the job monitor.
The job summary table:
Job log:
Job dependency tree:
Kill jobs: