Perform simplifyGO analysis with multiple lists of GO IDs
Source:R/simplify.R
simplifyGOFromMultipleLists.RdPerform simplifyGO analysis with multiple lists of GO IDs
Usage
simplifyGOFromMultipleLists(
lt,
go_id_column = NULL,
padj_column = NULL,
padj_cutoff = 0.01,
filter = function(x) any(x < padj_cutoff),
default = 1,
ont = NULL,
db = "org.Hs.eg.db",
measure = "Sim_XGraSM_2013",
heatmap_param = list(NULL),
show_barplot = TRUE,
method = "binary_cut",
control = list(),
min_term = NULL,
verbose = TRUE,
column_title = NULL,
...
)Arguments
- lt
A data frame, a list of numeric vectors (e.g. adjusted p-values) where each numeric vector has GO IDs as names, or a list of GO IDs.
- go_id_column
Column index of GO ID if
ltcontains a list of data frames.- padj_column
Column index of adjusted p-values if
ltcontains a list of data frames.- padj_cutoff
Cut off for adjusted p-values.
- filter
A self-defined function for filtering GO IDs. By default it requires GO IDs should be significant in at least one list.
- default
The default value for the adjusted p-values. See Details.
- ont
Pass to
GO_similarity().- db
Pass to
GO_similarity().- measure
Pass to
GO_similarity().- heatmap_param
Parameters for controlling the heatmap, see Details.
- show_barplot
Whether draw barplots which shows numbers of significant GO terms in clusters.
- method
Pass to
simplifyGO().- control
Pass to
simplifyGO().- min_term
Pass to
simplifyGO().- verbose
Pass to
simplifyGO().- column_title
Pass to
simplifyGO().- ...
Pass to
simplifyGO().
Details
The input data can have three types of formats:
A list of numeric vectors of adjusted p-values where each vector has the GO IDs as names.
A data frame. The column of the GO IDs can be specified with
go_id_columnargument and the column of the adjusted p-values can be specified withpadj_columnargument. If these columns are not specified, they are automatically identified. The GO ID column is found by checking whether a column contains all GO IDs. The adjusted p-value column is found by comparing the column names of the data frame to see whether it might be a column for adjusted p-values. These two columns are used to construct a numeric vector with GO IDs as names.A list of character vectors of GO IDs. In this case, each character vector is changed to a numeric vector where all values take 1 and the original GO IDs are used as names of the vector.
Now let's assume there are n GO lists, we first construct a global matrix where columns correspond to the n GO lists and rows correspond
to the "union" of all GO IDs in the lists. The value for the ith GO ID and in the jth list are taken from the corresponding numeric vector
in lt. If the jth vector in lt does not contain the ith GO ID, the value defined by default argument is taken there (e.g. in most cases the numeric
values are adjusted p-values, default is set to 1). Let's call this matrix as M0.
Next step is to filter M0 so that we only take a subset of GO IDs of interest. We define a proper function via argument filter to remove
GO IDs that are not important for the analysis. Functions for filter is applied to every row in M0 and filter function needs
to return a logical value to decide whether to remove the current GO ID. For example, if the values in lt are adjusted p-values, the filter function
can be set as function(x) any(x < padj_cutoff) so that the GO ID is kept as long as it is signfiicant in at least one list. After the filter, let's call
the filtered matrix M1.
GO IDs in M1 (row names of M1) are used for clustering. A heatmap of M1 is attached to the left of the GO similarity heatmap so that
the group-specific (or list-specific) patterns can be easily observed and to corresponded to GO functions.
Argument heatmap_param controls several parameters for heatmap M1:
transform: A self-defined function to transform the data for heatmap visualization. The most typical case is to transform adjusted p-values by-log10(x).breaks: break values for color interpolation.col: The corresponding values forbreaks.labels: The corresponding labels.name: Legend title.
Examples
# \donttest{
# perform functional enrichment on the signatures genes from cola anlaysis
require(cola)
#> Loading required package: cola
#> ========================================
#> cola version 2.6.0
#> Bioconductor page: http://bioconductor.org/packages/cola/
#> Github page: https://github.com/jokergoo/cola
#> Documentation: https://jokergoo.github.io/cola/
#> Examples: https://jokergoo.github.io/cola_collection/
#>
#> If you use it in published research, please cite:
#> Gu, Z. cola: an R/Bioconductor package for consensus partitioning
#> through a general framework. Nucleic Acids Research 2021.
#>
#> This message can be suppressed by:
#> suppressPackageStartupMessages(library(cola))
#> ========================================
data(golub_cola)
res = golub_cola["ATC:skmeans"]
require(hu6800.db)
#> Loading required package: hu6800.db
#> Loading required package: AnnotationDbi
#> Loading required package: stats4
#> Loading required package: BiocGenerics
#>
#> Attaching package: ‘BiocGenerics’
#> The following objects are masked from ‘package:stats’:
#>
#> IQR, mad, sd, var, xtabs
#> The following objects are masked from ‘package:base’:
#>
#> Filter, Find, Map, Position, Reduce, anyDuplicated, aperm, append,
#> as.data.frame, basename, cbind, colnames, dirname, do.call,
#> duplicated, eval, evalq, get, grep, grepl, intersect, is.unsorted,
#> lapply, mapply, match, mget, order, paste, pmax, pmax.int, pmin,
#> pmin.int, rank, rbind, rownames, sapply, setdiff, sort, table,
#> tapply, union, unique, unsplit, which.max, which.min
#> Loading required package: Biobase
#> Welcome to Bioconductor
#>
#> Vignettes contain introductory material; view with
#> 'browseVignettes()'. To cite Bioconductor, see
#> 'citation("Biobase")', and for packages 'citation("pkgname")'.
#> Loading required package: IRanges
#> Loading required package: S4Vectors
#>
#> Attaching package: ‘S4Vectors’
#> The following object is masked from ‘package:utils’:
#>
#> findMatches
#> The following objects are masked from ‘package:base’:
#>
#> I, expand.grid, unname
#> Loading required package: org.Hs.eg.db
#>
x = hu6800ENTREZID
mapped_probes = mappedkeys(x)
id_mapping = unlist(as.list(x[mapped_probes]))
lt = functional_enrichment(res, k = 3, id_mapping = id_mapping) # you can check the value of `lt`
#> - 2058/4116 significant genes are taken from 3-group comparisons
#> - on k-means group 1/4, 531 genes
#> Registered S3 methods overwritten by 'treeio':
#> method from
#> MRCA.phylo tidytree
#> MRCA.treedata tidytree
#> Nnode.treedata tidytree
#> Ntip.treedata tidytree
#> ancestor.phylo tidytree
#> ancestor.treedata tidytree
#> child.phylo tidytree
#> child.treedata tidytree
#> full_join.phylo tidytree
#> full_join.treedata tidytree
#> groupClade.phylo tidytree
#> groupClade.treedata tidytree
#> groupOTU.phylo tidytree
#> groupOTU.treedata tidytree
#> inner_join.phylo tidytree
#> inner_join.treedata tidytree
#> is.rooted.treedata tidytree
#> nodeid.phylo tidytree
#> nodeid.treedata tidytree
#> nodelab.phylo tidytree
#> nodelab.treedata tidytree
#> offspring.phylo tidytree
#> offspring.treedata tidytree
#> parent.phylo tidytree
#> parent.treedata tidytree
#> root.treedata tidytree
#> rootnode.phylo tidytree
#> sibling.phylo tidytree
#> - 478/531 (90%) genes left after id mapping
#> - gene set enrichment, GO:BP
#> - on k-means group 2/4, 811 genes
#> - 640/811 (78.9%) genes left after id mapping
#> - gene set enrichment, GO:BP
#> - on k-means group 3/4, 315 genes
#> - 276/315 (87.6%) genes left after id mapping
#> - gene set enrichment, GO:BP
#> - on k-means group 4/4, 401 genes
#> - 374/401 (93.3%) genes left after id mapping
#> - gene set enrichment, GO:BP
# a list of data frames
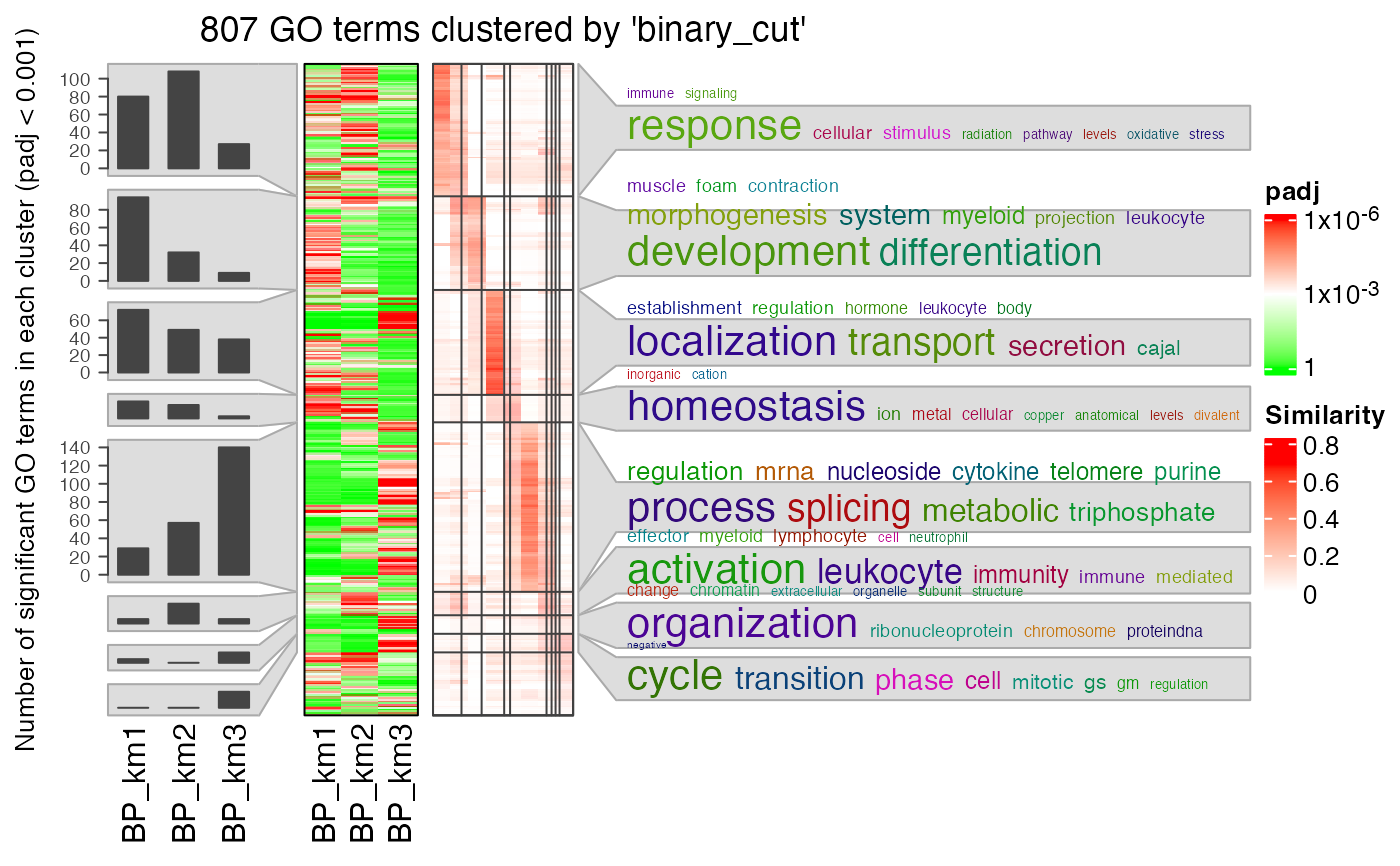
simplifyGOFromMultipleLists(lt, padj_cutoff = 0.001)
#> Use column 'ID' as `go_id_column`.
#> Use column 'p.adjust' as `padj_column`.
#> Loading required namespace: gridtext
#> 822/6404 GO IDs left for clustering.
#> You haven't provided value for `ont`, guess it as `BP`.
#> term_sim_method: Sim_XGraSM_2013
#> IC_method: IC_annotation
#> Cluster 822 terms by 'binary_cut'...
#> 27 clusters, used 8.770008 secs.
#> Perform keywords enrichment for 7 GO lists...
 # a list of numeric values
lt2 = lapply(lt, function(x) structure(x$p.adjust, names = x$ID))
simplifyGOFromMultipleLists(lt2, padj_cutoff = 0.001)
#> 822/6404 GO IDs left for clustering.
#> You haven't provided value for `ont`, guess it as `BP`.
#> term_sim_method: Sim_XGraSM_2013
#> IC_method: IC_annotation
#> Cluster 822 terms by 'binary_cut'...
#> 31 clusters, used 8.559243 secs.
#> Perform keywords enrichment for 8 GO lists...
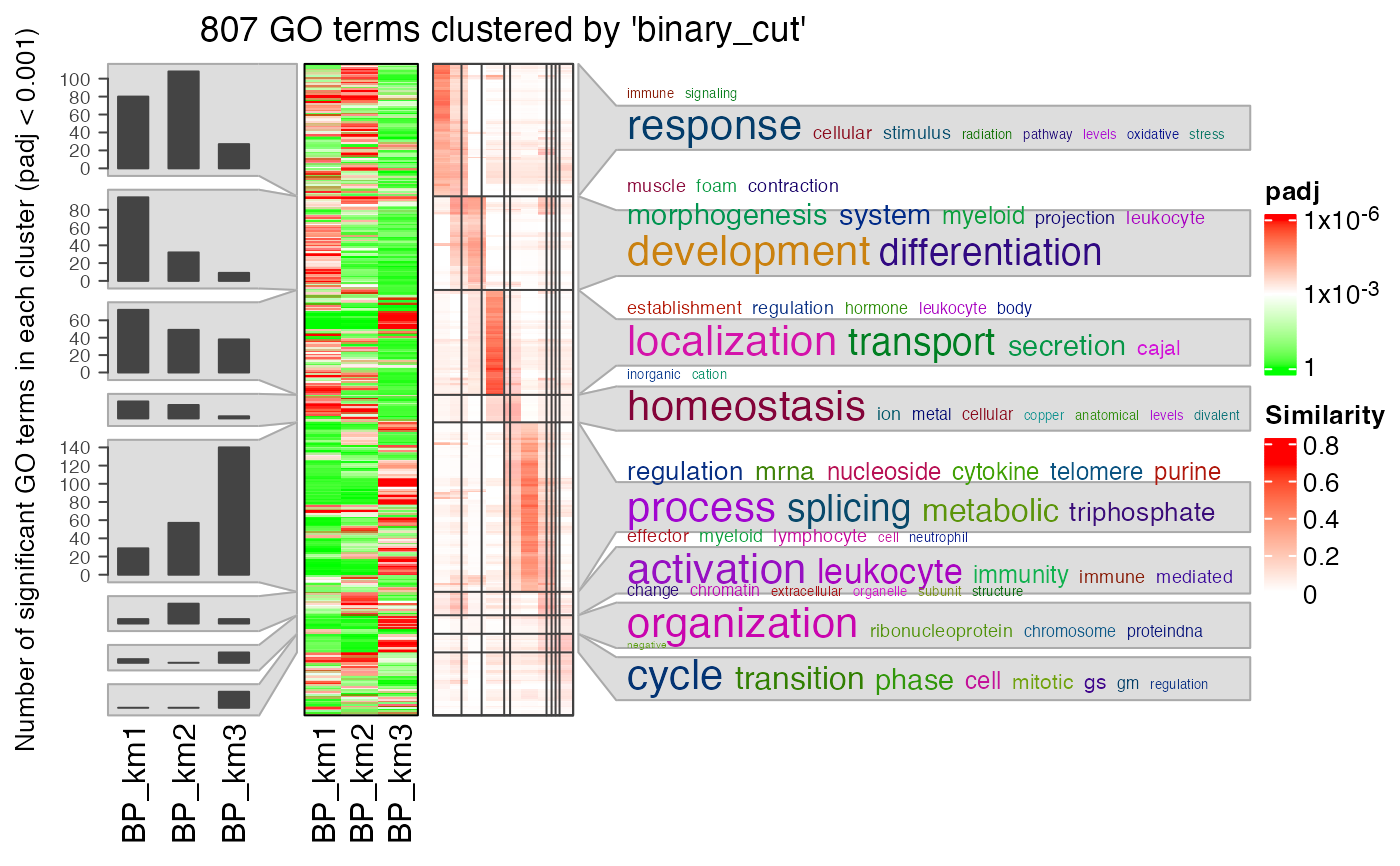
# a list of numeric values
lt2 = lapply(lt, function(x) structure(x$p.adjust, names = x$ID))
simplifyGOFromMultipleLists(lt2, padj_cutoff = 0.001)
#> 822/6404 GO IDs left for clustering.
#> You haven't provided value for `ont`, guess it as `BP`.
#> term_sim_method: Sim_XGraSM_2013
#> IC_method: IC_annotation
#> Cluster 822 terms by 'binary_cut'...
#> 31 clusters, used 8.559243 secs.
#> Perform keywords enrichment for 8 GO lists...
 # a list of GO IDS
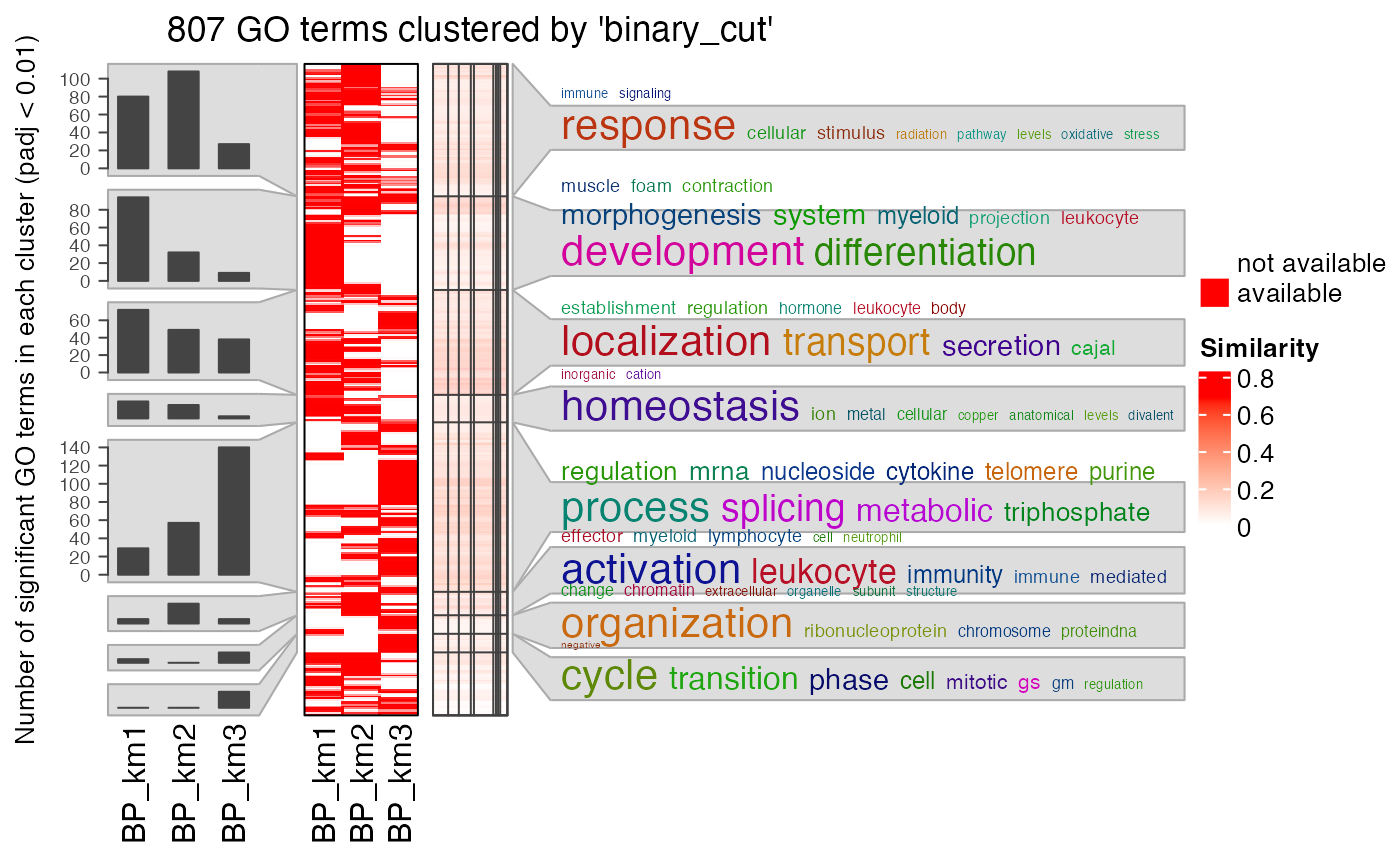
lt3 = lapply(lt, function(x) x$ID[x$p.adjust < 0.001])
simplifyGOFromMultipleLists(lt3)
#> 822/822 GO IDs left for clustering.
#> You haven't provided value for `ont`, guess it as `BP`.
#> term_sim_method: Sim_XGraSM_2013
#> IC_method: IC_annotation
#> Cluster 822 terms by 'binary_cut'...
#> 23 clusters, used 9.059406 secs.
#> Perform keywords enrichment for 9 GO lists...
# a list of GO IDS
lt3 = lapply(lt, function(x) x$ID[x$p.adjust < 0.001])
simplifyGOFromMultipleLists(lt3)
#> 822/822 GO IDs left for clustering.
#> You haven't provided value for `ont`, guess it as `BP`.
#> term_sim_method: Sim_XGraSM_2013
#> IC_method: IC_annotation
#> Cluster 822 terms by 'binary_cut'...
#> 23 clusters, used 9.059406 secs.
#> Perform keywords enrichment for 9 GO lists...
 # }
# }